
Over the last few months I have been developing a pipeline for using AI agents in software development. To facilitate this, I have developed an orchestration layer that sits in between the programmer’s intent and the agents that create the code. This orchestration layer, or Agent Cluster, is comprised of 16 subagents, all performing very specific tasks.
Despite my many efforts, the output I was receiving at the end of the pipeline were deviating from my original intent. This problem caused me to really think and evaluate at what point my Agent Cluster was breaking down.
It was not the capabilities of the models that caused the problems. It was not the ability of the programmer to engineer a suitable prompt for the model. And, while there were limitations to the size of the context windows used by the models, it was not the size of the context window that was the issue. The problem was the quality of the scope document that was being passed to the agent. Over a two month period, I reviewed all of the failed agent runs for which I had documentation of the scope. Roughly 50 percent of those failures were silent failures; i.e., the agent completed its run without crashing or throwing an exception, but produced an incorrect output. The reason for the incorrect output was that there was some ambiguity, contradiction or omission in the scope.
For example, the scope document instructed the agent to “add notification preferences” without specifying if the notification preferences should be for email, push, SMS, or all three. The agent registered a service worker and implemented a complete multi-channel notification system. The client simply wanted to include a few toggle options for email notifications. The Agents not being given explicit instructions performed their own unsupervised reasoning and came up with a solution well beyond the client intent.
As part of this resolution I spent hours researching the current research and literature on the topic and I wanted to share what I learned because I believe that the findings are important and relevant to anyone who is considering implementing AI agents in their programming workflow.
CodeScout, a research group that posted a paper titled “CodeScout: Understanding What Makes Bug Reports Resolvable by AI Agents” on arXiv in March 2026 conducted a study to determine what factors differentiate between bug reports that AI agents can resolve and those that cannot. Their results showed that resolvable bug reports have description quality scores that range from 110% to 2700% greater than those that are not resolvable. That’s a significant margin of error — nearly twenty seven times greater.
Description quality was identified as the number one factor in determining whether the agent could resolve the bug. That’s prior to any code analysis or model inference. The researchers at CodeScout created a repository knowledge graph to provide a basis for their study based on the underlying structure of the codebases. The knowledge graph provided a level of abstraction that allowed the researchers to measure the impact of description quality on success even after the application of all of the machine learning machinery available to the researchers.
These findings support the results of research conducted by Qodo regarding the effectiveness of code review. Qodo developed an alignment phase as part of their code review toolset that occurs before any code analysis. The alignment phase is designed to understand the intent behind the code and develop a structured context object that will guide all subsequent analysis. The researchers at Qodo reported that the effectiveness of providing a pre-defined context object resulted in actionable feedback for the agent; whereas without the alignment phase the agent generated nothing but noise.
I was curious to see if the results from CodeScout and Qodo represented general principles applicable to multiple types of AI applications or if they were specific to bug reporting and code review. Researchers in the field of requirements engineering define a framework called the QUS framework that includes five dimensions for assessing the quality of user stories: Feature Specificity, Rationale Clarity, Problem-Oriented Framing, Language Clarity and Internal Consistency. When I compared the failed agent runs to the five dimensions defined in the QUS framework, every failed agent run contained at least two violations of the five dimensions, and most contained three or four violations.
Another finding from the same research is that large language models (LLMs) improve by 20.2% in determining the clarity of ambiguous requirements when provided with only 10 examples of ambiguous vs. unambiguous statements. Therefore, it is possible to train an LLM to detect the kind of ambiguities that can lead to failure of downstream agents prior to the agents commencing operation.
However, the authors also noted that human evaluators consistently rated requirements written by analysts as less ambiguous than requirements written by LLMs, especially in terms of language clarity. While machines can identify structural issues more easily, humans can identify linguistic ambiguities more easily. Therefore, both are necessary.
Why does this matter now?
IEEE Spectrum recently wrote an article stating that AI coding assistants have hit a quality plateau, and newer models generate code that appears correct but quietly fail. Since 42% of all new code is currently AI-assisted, as indicated by Sonar’s 2026 Benchmark Data, this represents a growing concern.
The industry has recognised the importance of requirements ambiguity for decades. However, in the rush to develop AI coding agents, the principle that output quality is limited by input quality appears to have been ignored.
A skilled human developer will read an ambiguous scope document and stop and ask questions. A human developer will use their experience to fill in the gaps and/or will flag the ambiguity prior to generating code. An AI agent does not behave similarly. It selects an interpretation and generates code accordingly. You will not realise that the selected interpretation was the incorrect interpretation until you review the Pull Request (PR).
The Azure Architecture Center stated this point well: validate the output of an AI agent before forwarding the output to the next agent, since low-confidence or off-topic responses propagate throughout the pipeline. This principle applies upstream as well. If the scope document contains ambiguity, the ambiguity does not remain static. The ambiguity propagates. Each downstream agent interprets the ambiguity separately. Prior to reaching the fourth agent in a pipeline, the cumulative effect of the ambiguity can result in a final product that is significantly different from the original intent.
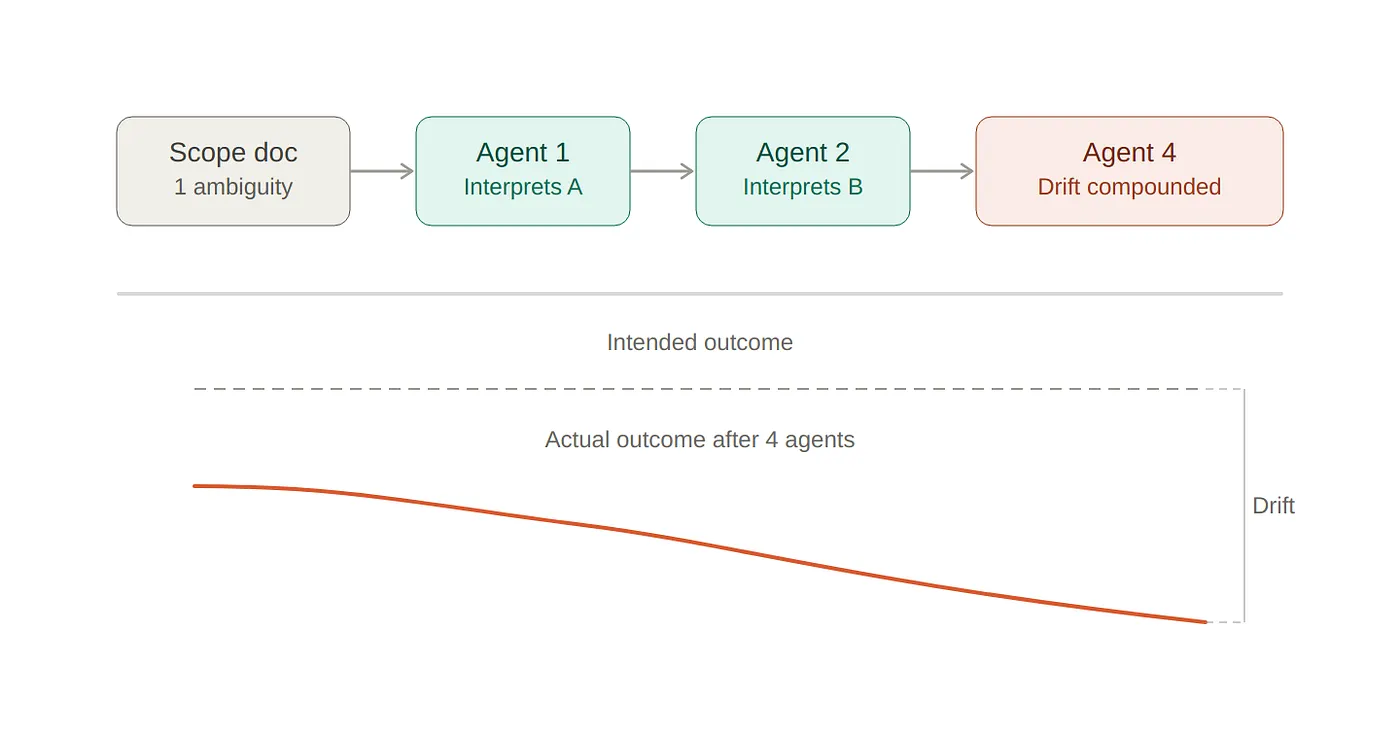
Validation of scopes as a solvable problem
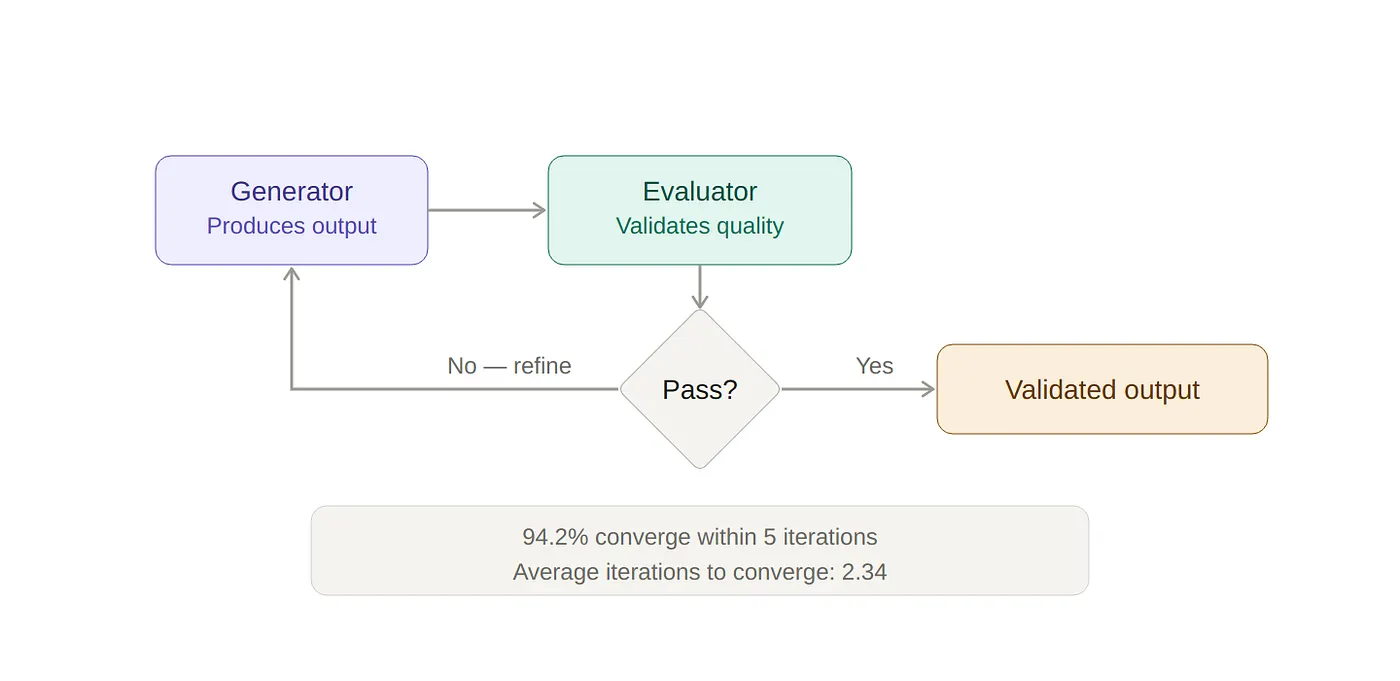
The medical AI research community has been researching evaluation loops. An evaluation loop is simple in concept. The output of an AI agent is validated by another agent. Questions are generated and answered by humans. The loop repeats until the quality of the output converges. A January 2026 study published in Nature evaluated the effectiveness of this method in a clinical setting. The researchers found that 94.2% of the evaluations converged within five iterations. The average number of iterations required to converge was 2.34.
Two to three iterations of structured validation by a human inputter, along with an additional iteration to confirm that the output meets the desired quality standard, is sufficient to resolve most ambiguity and meet a quality standard for the output.
The evaluator-optimiser pattern is well-documented across AWS, Anthropic, and other production multi-agent systems. A generator produces output. An evaluator validates the quality of the output. The loop continues until the output meets the desired quality standard or the maximum number of retries has been exceeded. Use this same pattern to validate the scope document and you have a viable solution.
ARIA, TikTok Pay’s AI system that serves 150 million users per month, utilises a similar approach. Instead of asking the human to answer open-ended clarification questions, ARIA presents the human with specific questions that are accompanied with suggested answers. The human verifies or corrects the answers. The convergence rate is faster because the cognitive load is reduced.
One of the key takeaways from this research is that validating the scope document is not about creating a perfect scope document upfront. It is about creating a system that identifies ambiguity early, provides the human with targeted questions, and continues to iterate until the scope document is sufficiently clear for the agent to operate correctly.
What am I building next?
I have developed a scope validation system that resides between the human-written scope document and the AI coding agent. The system utilises three sub-agents operating in parallel and utilises the actual structure of the codebase as a basis for its analysis. One of the sub-agents analyses the scope document to ensure that it is consistent with the existing code. A second sub-agent analyzes the scope document from a linguistic and requirements perspective. The third sub-agent synthesizes the results of the first two sub-agents into a confidence score and a list of targeted questions to be asked of the human.
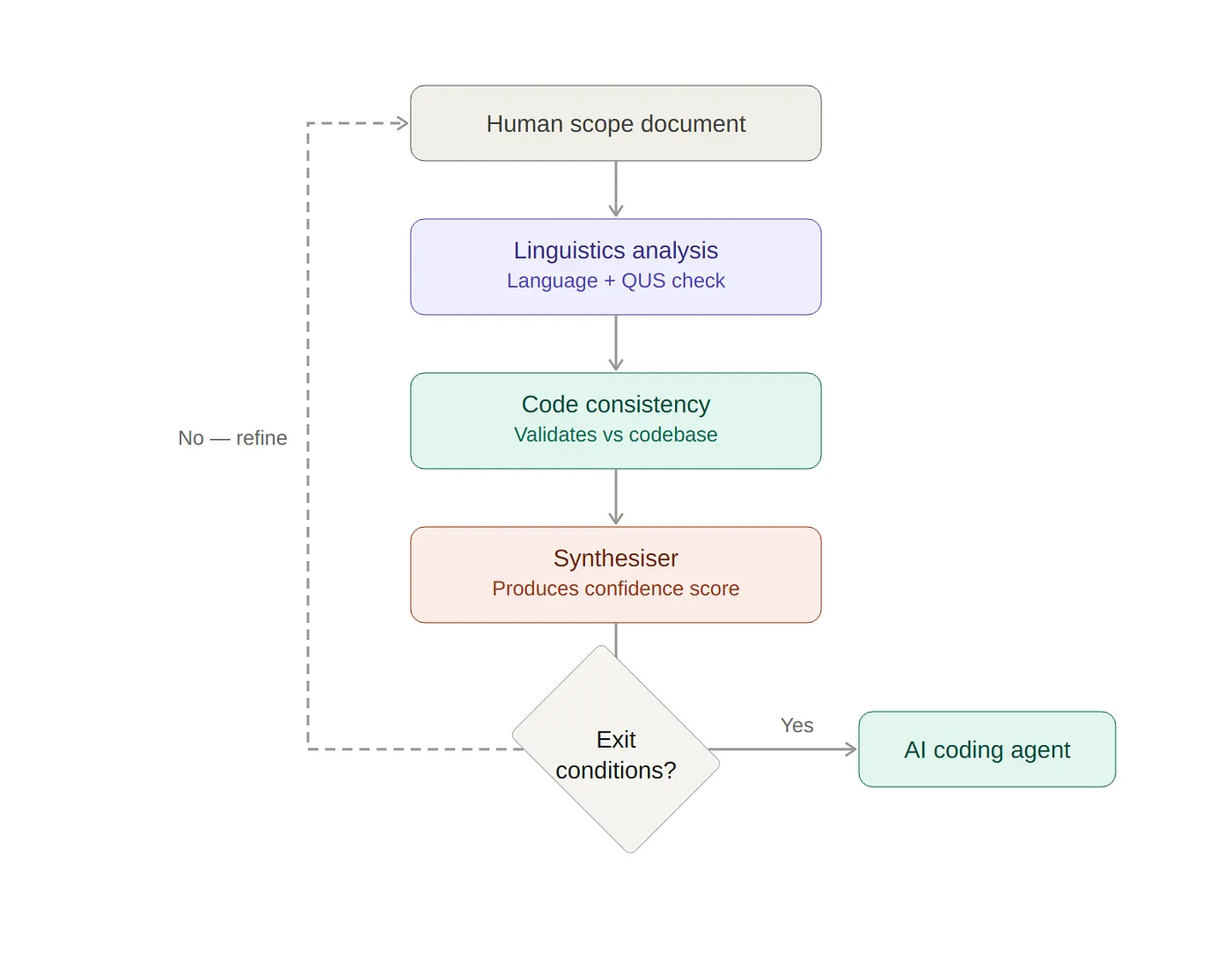
In the next post I will describe the entire architecture of the system, why separate evaluators outperform a monolithic analyser (as demonstrated by the AIME Evaluator Ensemble Work) and the methods for detecting convergence.
More broadly, the current conversation regarding AI code quality in 2026 is missing a critical discussion regarding AI input quality — the scope documents that are fed to these agents. That is where the largest improvements are likely to be achieved.
You May Also Like
How RailsInsight Gives AI Agents Structural Understanding of Your Rails App
Why Does Your AI Agent Forget What You Told It? (And How to Make It Remember?)
Ps. if you have any questions
Ask here