

What is covered in this article
In this article you will create a Q&A application based on knowledge articles from your own website. You will use GPT-3 to make it respond intelligently and code it in Ruby.
The example in this article is based on an e-commerce company called Sterling Parts that’s sells car parts. Users will be able to ask the AI questions which are answered in Sterling Parts “frequently asked questions”, “about “us and “terms of use” pages.
In a future article you will learn how to create a Q&A that can ask questions related to the products on the e-commerce page as well.
Technical Assistance:
We can help you to create the knowledge base!
- Matenia Rossides, Engineering Manager, reinteractive.
- Miguel Dagatan, Senior Rails Developer, reinteractive.
- Allan Andal, Senior Rails Developer, reinteractive
Prerequisites
In order to follow along with this articles you need to have the following knowledge:
- Intermediate knowledge of Ruby
- An understanding of how to integrate Ruby with Openai
Github
The code for this article is available on Github:
https://github.com/reinteractive/gpt3-embeddings
Summary of the Process
You will be creating two Ruby scripts that can be used to prepare the knowledge base and ask GPT-3 questions about the knowledge base. It will work similarly to ChatGPT except you will train the model to answer specifically based on the knowledge from your website.
In order to make this process work you will use arrays known in Machine Learning as Vector embeddings. Embedding is the process of converting a section of text into an array of numbers.
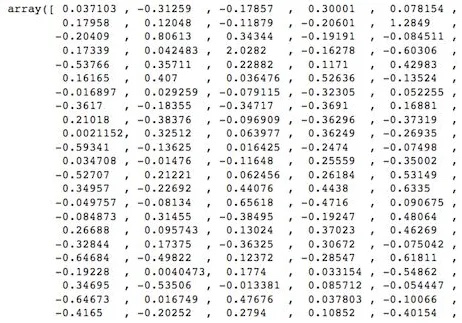
This vector is a numerical representation of the meaning contained in the text.
These vectors permit semantic search to find the most relevant information in the knowledge base and then utilise GPT-3 to provide a meaningful answer to the users question.
The word “semantic” refers to the meaning of language. As a Ruby developer you would be familiar with keyword searching, which finds exact or partial matches of words within a database. Semantic search finds matches in a database based on the meaning or intent of a question.
Example:
Question: “How to I cut apples?”
Knowledge article 1:“In order to peel an orange you first need to get an orange peeler.”
Knowledge article 2:“If you want to slice up an apple you will first need to get a sharp knife.”
Semantic search will return knowledge article 2 as the most relevant. It is sufficiently “intelligent” to understand that cut and slice and semantically similar.
There is quite some complex mathematics that goes behind this. I am currently writing an article detailing the mathematics which will be released soon, if you are interested.
To achieve semantic search, your application needs to convert text into vector embeddings.
GPT-3 has an embedding endpoint which will convert your text into a vector of 1500 values. Each value in the vector represents a feature of the text.
Some examples of different features that might be represented in a vector embedding include:
- Semantic meaning
- Parts of speech
- Frequency of use
- Associations with other words
- Grammatical structure
- Sentiment
- Text length
As GPT-3 has token limits, the knowledge base needs to be broken down into chunks no more than about 3000 tokens in total (about 2000 words). Each chunk is converted into a vector and stored in a database to be searched against.
When a user asks a question, this question is also converted into a vector, and using a specific mathematical process, is used to search the database to find the knowledge base chunk which has the most relevant meaning.
From there we send the question and knowledge based chunk to GPT-3 to respond with a meaningful answer.
Step One: Preparing the Data
Since GPT-3 has a 4096 total token limit for prompt plus response, it is important to convert the knowledge based data into chunks of approximately 2000 words. We need enough space for the question tokens and the response tokens.
Where possible it is valuable to create chunks that have similar meaning. For the Sterling Parts website the FAQ, About Us and Terms of Use are all under 1000–2000 words each, it makes semantic sense to covert each individual page into its own text file.
In your Ruby application create a folder called training-data.

Visual Studio with training-data folder
The training-data folder will contain the knowledge base text for your application. These will be stored as standard .txt files. For this example using the Sterling Parts website, the following web pages will be stored as text files.
https://www.sterlingparts.com.au/faqs
https://www.sterlingparts.com.au/about-us
https://www.sterlingparts.com.au/Terms-and-Conditions
The terms and conditions page is the largest at 2008 words. For your purposes take your content and copy and paste it into text files within the training-data folder.
It doesn’t matter what the files are called so long as they are .txt files.

Knowledge base data in text files
Step Two: Converting Data into Vector Embeddings
You will need the ruby-openai gem in order to work with the OpenAI API.
Install the required gems.
gem install ruby-openai dotenv
Ensure you have your OpenAI API key saved in the .env file.
Import the openai library, and create a new instance using your API key.
# embeddings.rb
require 'dotenv'
require 'ruby/openai'
Dotenv.load()
openai = OpenAI::Client.new(access_token: ENV['OPENAI_API_KEY'])
Next is the process to extract all of the text files data. In Ruby you will loop through the training-data folder, read the data from each text file and store this data in an array.
# embeddings.rb
# The array will be used to hold the data from each file
text_array = []
# Loop through all .txt files in the /training-data folder
Dir.glob("training-data/*.txt") do |file|
# Read the data from each file and push to the array
# The dump method is used to convert spacings into newline characters \n
text = File.read(file).dump()
text_array << text
end
With all the training data in the text_array the next step is to convert each body of text into a vector embedding. To do this you will use the OpenAI embeddings endpoint. The endpoint takes two parameters, the model which is text-embedding-ada-002 and the input which is the text from each file.
# embeddings.rb
# This array is used to store the embeddings
embedding_array = []
# Loop through each element of the array
text_array.each do |text|
# Pass the text to the embeddings API which will return a vector and
# store in the response variable.
response = openai.embeddings(
parameters: {
model: "text-embedding-ada-002",
input: text
}
)
# Extract the embedding from the response object
embedding = response['data'][0]['embedding']
# Create a Ruby hash containing the vector and the original text
embedding_hash = {embedding: embedding, text: text}
# Store the hash in an array.
embedding_array << embedding_hash
end
You can print the embedding variable and you will see a vector of 1500 values. This is your vector embedding.
The embedding_array stores the values of the vector embeddings and original text which will be stored in our database for semantic search purposes.
Step Three: Storing the embeddings in the CSV (database)
For the purposes of this article a CSV file is being used to substitute for a database. There are specialised vector databases that have very efficient semantic search algorithms. From a Ruby perspective the most useful tool is Redis. It contains a vector search feature. This link provides more information: https://redis.com/blog/rediscover-redis-for-vector-similarity-search/
In this step, a CSV file is created which includes two columns embedding and text. This CSV stores the original text from each file along with its vector embedding. You will need to import the csv library for this step.
# embeddings.rb
require 'dotenv'
require 'ruby/openai'
require 'csv'
This is the final code for the embeddings.rb script. It will create a CSV file with the embedding and textheaders, loop through the embedding_array and save the respective vector embeddings and text into the CSV.
embeddings.rb
CSV.open("embeddings.csv", "w") do |csv|
# This sets the headers
csv << [:embedding, :text]
embedding_array.each do |obj|
# The embedding vector will be stored as a string to avoid comma
# sperated issues between the values in the CSV
csv << [obj[:embedding], obj[:text]]
end
end
The final action for the embeddings.rb script is to run it and populate the CSV file with the data.
ruby embeddings.rb
Once run the file structure will look like this.
Visual Studio Code File Structure.
Step Four: Get the question from the user
Now it’s time to turn your attention to the next Ruby script questions.rb . This is the main file which will be run to query the users question against the CSV of vectors, returning the original text that has the closest semantic similarity and get GPT-3 to return an intelligent answer.
Generally speaking you would be running this inside a Rails application and getting the users question from a text field from your view. This example will stick to the CLI to keep things simple.
Create a new file questions.rb and import the required library.
# questions.rb
require 'dotenv'
require 'ruby/openai'
require 'csv'
Dotenv.load()
openai = OpenAI::Client.new(access_token: ENV['OPENAI_API_KEY'])
You need to get the users question, which will be used to query the knowledge base.
# questions.rb
puts "Welcome to the Sterling Parts AI Knowledge Base. How can I help you?"
question = gets
Using the embeddings OpenAI endpoint, the users question can be converted into a vector embedding. This will permit the use of a mathematical formula to find the text in the embeddings.csv file with the closest meaning and intent.
# questions.rb
# Convert the question into a vector embedding
response = openai.embeddings(
parameters: {
model: "text-embedding-ada-002",
input: question
}
)
# Extract the embedding value
question_embedding = response['data'][0]['embedding']
Printing the embedding will show you an array of 1500 values. This is your vector embedding.
Step Five: Search the CSV to find the text with the closest semantic meaning to the question.
This is where the mathematics comes in. I am in the process of writing a detailed article on the mathematics of vector embeddings and how to search for closest semantic meaning. For now let’s keep it simple.
The mathematics used is called cosine similarity. If you recall from high school mathematics the cosine is used in trigonometry to find the angle of a triangle. In Machine Learning cosine similarity is used to find the similarity between two vectors. This is simple to represent in two dimensions. In two dimensions a vector has two values and can be plotted on a graph.
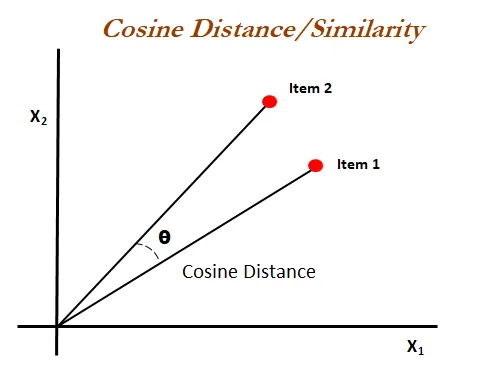
Source: Statistics for Machine Learning by Pratap Dangeti
Cosine similarity can be used to determine the relationship between the two vectors. It is represented between 0 and 1, with 1 indicating identical vectors.
With vector embeddings, you are dealing with vectors of 1500 values. It is impossible to visually represent this, but nevertheless the mathematics works the same.
By using cosine similarity, the computer can determine which text file contains meanings most closely related to the users question.
I created the cosine-similarity Ruby gem that will perform the mathematics without the need to understand its inner workings.
gem install cosine-similarity
Import the library at the top of the questions.rb file.
# questions.rb
require 'dotenv'
require 'ruby/openai'
require 'csv'
require 'cosine-similarity'
The next step is to loop through all rows of the CSV file, and compare the question vector to the original text vectors. The cosine_similarity method will compare the question against each of the original texts and will return a number between 0 and 1.
You are interested in the similarity with the highest value. This is the text with the closest meaning and intent to the question.
# questions.rb
# Store the similairty scores as the code loops through the CSV
similarity_array = []
# Loop through the CSV and calculate the cosine-similarity between
# the question vector and each text embedding
CSV.foreach("embeddings.csv", headers: true) do |row|
# Extract the embedding from the column and parse it back into an Array
text_embedding = JSON.parse(row['embedding'])
# Add the similarity score to the array
similarity_array << cosine_similarity(question_embedding, text_embedding)
end
# Return the index of the highest similarity score
index_of_max = similarity_array.index(similarity_array.max)
The index_of_max variable now contains the index of the highest similarity score. This can be used to extract the text from the CSV that is needed to send to GPT-3 along with the users question.
# questions.rb
# Used to store the original text
original_text = ""
# Loop through the CSV and find the text which matches the highest
# similarity score
CSV.foreach("embeddings.csv", headers: true).with_index do |row, rowno|
if rowno == index_of_max
original_text = row['text']
end
end
Step Six: Pass the user question and knowledge based text to the GPT-3 completions endpoint
Continuing with the questions.rb file. The script is now storing the users question and the original_text which have the closest meaning. It is now possible to pass this information to GPT-3 completions endpoint to return an intelligent response to the users question.
A tailored prompt is necessary in order to prime GPT-3 to respond in an appropriate manner that aligns with the users question and the purpose of the knowledge base. This falls within the scope of prompt design.
prompt =
"You are an AI assistant. You work for Sterling Parts which is a car parts
online store located in Australia. You will be asked questions from a
customer and will answer in a helpful and friendly manner.
You will be provided company information from Sterling Parts under the
[Article] section. The customer question will be provided under the
[Question] section. You will answer the customers questions based on the
article.
If the users question is not answered by the article you will respond with
'I'm sorry I don't know.'
[Article]
#{original_text}
[Question]
#{question}"
The key to a successful prompt is providing sufficient information to GPT for it to form a pattern of response. The first paragraph primes GPT on how it will respond to the users question.
The second paragraph provides the context for GPT so it can determine what information it will use to respond with.
At the bottom of the prompt the original_text and question are injected from your previous steps.
Note: If you find you are not getting the best response from GPT, it is often necessary to modify and experiment with the prompt. Take advantage of the OpenAI playground to test your prompt until you get it right. https://platform.openai.com/playground
The prompt is now passed to GPT’s completion endpoint to return an intelligent response.
response = openai.completions(
parameters: {
model: "text-davinci-003",
prompt: prompt,
temperature: 0.2,
max_tokens: 500,
}
)
The temperature is quite low in the code. This will ensure GPT returns a very high probability response. If you want GPT to be more creative with its response, increase the temperature towards 0.9.
This endpoint will generate a response within a few seconds (depending of server load).
Step Seven: Get the response from GPT-3 and display it to the user.
The final step is to output GPT’s response to the user.
puts "\nAI response:\n"
puts response['choices'][0]['text'].lstrip
Your script is complete!
Debugging the Response
There are three potential factor that can cause GPT to return a response that does not meet your requirements.
- Data preparation
- Prompt design
- Temperature parameter
We can help you create your knowledge base with our AI Integration Service
Data Preparation
As best as possible, attempt to create each file so that it contains similar meaning. If one file cuts off half-way through a sentence and the next file picks up midway, you may have trouble finding the exact text you need to feed GPT.
You are better breaking files up into smaller, but meaningfully group texted to improve your similarity searches.
Prompt Design
This one takes practice!
As a general rule, the clearer and more explicit you are in the prompt, the better GPT will be able to generate results tailored to your needs.
There is no substitute for trail and error on this one. If you get stuck, feel free to reach out to me directly and I will happily give you a hand. (My details are at the end of the article).
Temperature Parameter
I have an article on fully understanding the temperature parameter (see below.)
In simple terms the temperature controls the randomness or ‘creativity’ of the model. A low temperature will provide more expected responses, while higher temperatures provide more creative responses. Depending on your needs, play with the temperature until you get the desired results.
Mastering the GPT-3 Temperature Parameter with Ruby In previous articles I have covered how you can use OpenAI in your Ruby application to take advantage of the GPT-3 AI… ai.plainenglish.io
Improving the Model
You may have very specific use cases that require additional training of the model to provide the types of responses that are appropriate to your knowledge base and users.
There are several approaches, which will be covered in later articles, but these boil down in inline-priming and fine-tuning.
Inline-priming is providing examples of questions and answers within the prompt. This is useful if you need GPT to respond in a very particular format or way. I use this frequently when I need a response in JSON.
Fine-tuning is another approach altogether and is used to train your own GPT model to perform tasks it hasn’t been trained on before. This is useful for asking users questions to extract particular information.
Next Steps
The next area I am working on is using vector embeddings for product search. That is allowing a user to ask a question and have GPT respond with appropriate products.
I know the general pattern to achieve this, I just need a spare 20 hours to write the code, test and write the article. So stay tuned.
